MLLM
2025年11月9日 · 455 字 · 3 分钟
这篇博客系统性地介绍 SOTA 的开源 MLLM,包括 Qwen-VL 系列,InternVL, Pixtral 等。
Qwen-VL Series
Qwen-VL
Qwen-VL 是 Qwen 系列第一个 VLM 模型,可以解决一些 vision-language 任务,比如 image caption,QA,grounding 等。
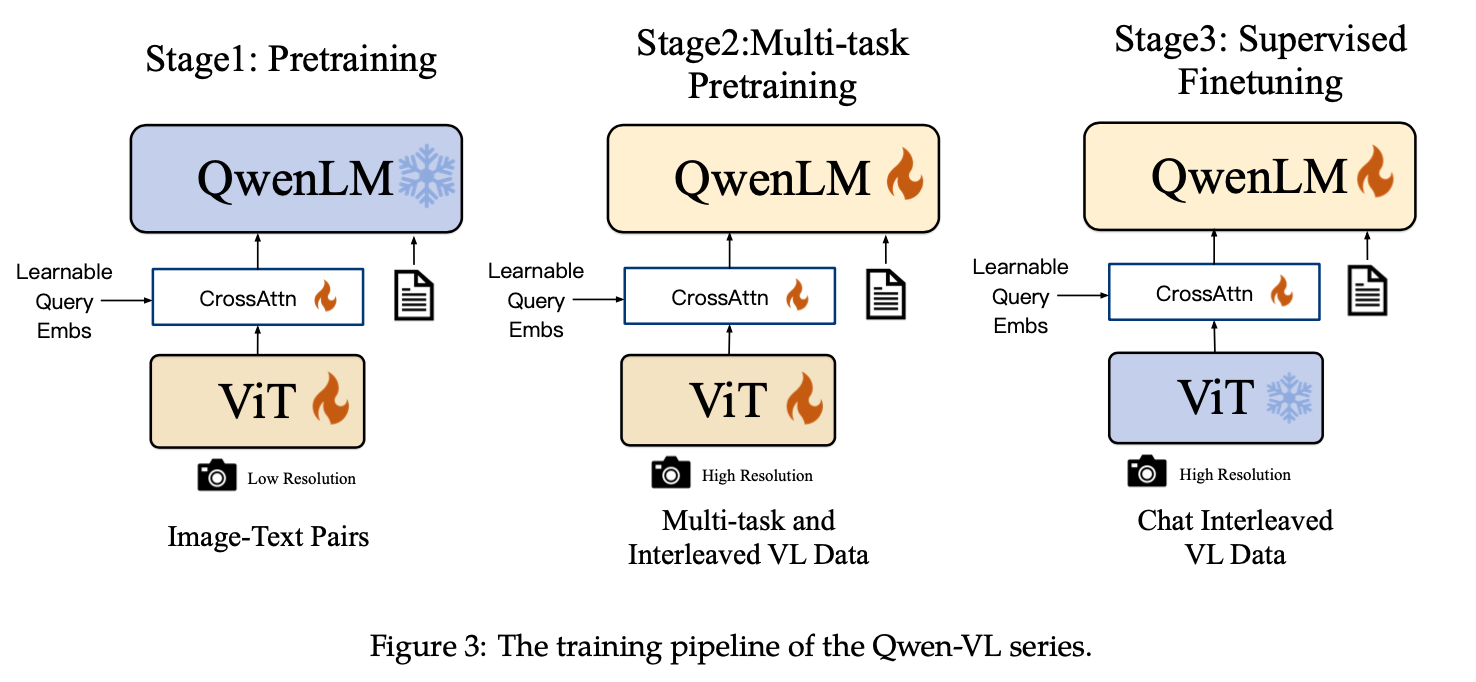
模型设计
Qwen-VL 由三个核心部分构成:
- LLM:使用 Qwen-7B 进行初始化
- ViT:使用 Openclip 的 ViT-bigG 预训练权重进行初始化
- Position-aware Vision-Language Adapter:一个随机初始化的单层 cross-attention 模块,该模块使用一组可训练向量作为 query 向量,使用来自 ViT 的图像特征作为 key 进行 cross-attention 操作。这种机制将视觉特征序列压缩到256的固定长度。考虑到位置信息对于细粒度图像理解的重要性,在 cross-attention 机制的 query-key 对中加入了2D绝对位置编码,以减轻压缩过程中潜在的位置细节丢失。长度为256的压缩图像特征序列随后被输入到大语言模型中。
为什么要使用可学习的 Query 作为 Adapter?
直接使用 ViT 的输出作为 LLM 的输入存在严重的效率问题。对于 448×448 的输入图像,ViT 会输出长度为 1024 的特征序列,而 LLM 中的 self-attention 机制具有 $O(n^²)$ 的计算复杂度,这会导致计算成本过高、推理速度慢,并且大量占用 LLM 的上下文窗口。可学习的 Query 提供了一种优雅的解决方案:通过 cross-attention 机制,256 个可学习的 query embedding 在训练过程中学会如何从冗长的视觉特征中提取最关键的信息,类似于“用 256 个问题来总结图像内容”,每个 query 可以专注于不同方面的视觉模式(如物体、纹理、空间关系等)。这种设计带来了两个重要优势:一是实现了信息压缩,将 1024 维序列压缩到固定的 256 维,大幅降低了计算成本;二是保证了固定长度输出,无论输入图像分辨率多大,输出始终是 256,使得 LLM 端的架构设计更加简洁统一。
模型训练
Stage-1: 预训练
预训练的数据是 image-text 对,原始数据 50 亿对,清洗后剩余 14 亿对,包含 22.7% 中文和 77.3% 英文。
在这一阶段,LLM 骨干参数被冻结,仅调整 ViT 和 adapter,输入图像被调整为224 × 224。
Stage-2: 多任务预训练
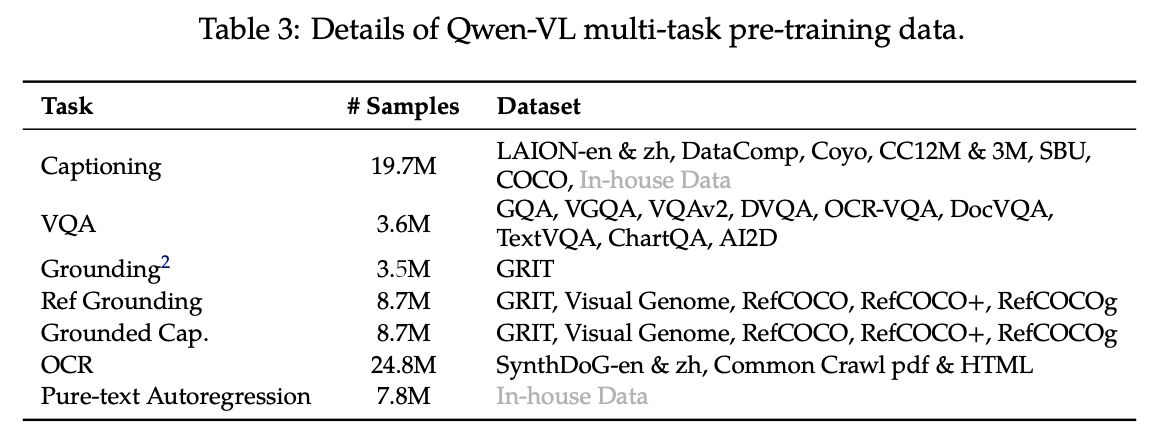
这一阶段引入了高质量和细粒度的VL标注数据,使用更大的输入分辨率和交错的 image-text 数据(多张图像输入),将视觉encoder的输入分辨率从224 × 224提高到448 × 448,减少了图像下采样造成的信息损失。
此外,为了缓解模型知识遗忘的问题,还引入了部分 In-house 数据集进行纯文本的自回归。
具体而言,各个任务对应的模型输出格式如下所示:
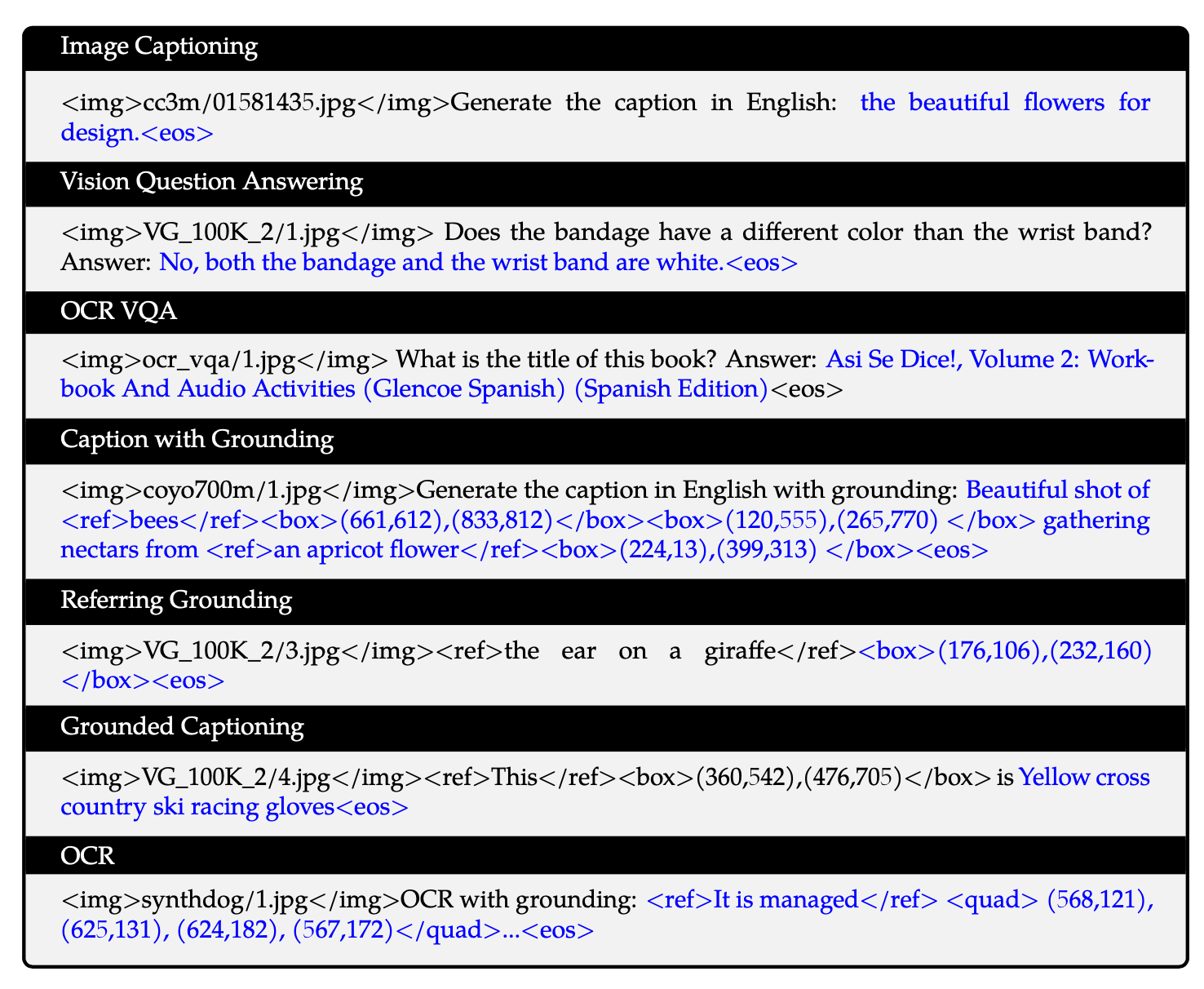
Stage-3: SFT
这一阶段通过 instruction tuning 得到 Chat 模型,通过混合多模态和纯文本的对话数据,确保模型在对话能力方面的通用性,一共 35w 条训练样本。数据格式如下:

实验验证
Window Attention vs Global Attention for ViT
使用高分辨率的 ViT 会增加计算成本,一种可能的优化方案是大部分层使用 Window Attention,只在 224x224 的窗口内做 attention,少数层使用 Global Attention (整个 448x448 或 896x896)。
实验表明,Window Attention 不会带来明显的速度优势,反而性能下降,因此 Qwen-VL 采用 Global Attention。
Qwen2-VL
Qwen2-VL 相比于第一代模型的改进之处还是蛮多的。主要有以下几个方面:
- 支持各种分辨率和宽高比 在第一代模型里面,不管输入大小多大,都会被 resize 到固定大小,这种“一刀切”的模式会限制模型在不同尺度上捕捉信息的能力
- 超长视频理解 上一代模型仅支持图像输入,而 Qwen2-VL 允许输入超过 20 分钟的视频
- Agent能力
- 多语种支持 除了英文和中文,还支持日语、越南语、欧洲语言等
模型设计
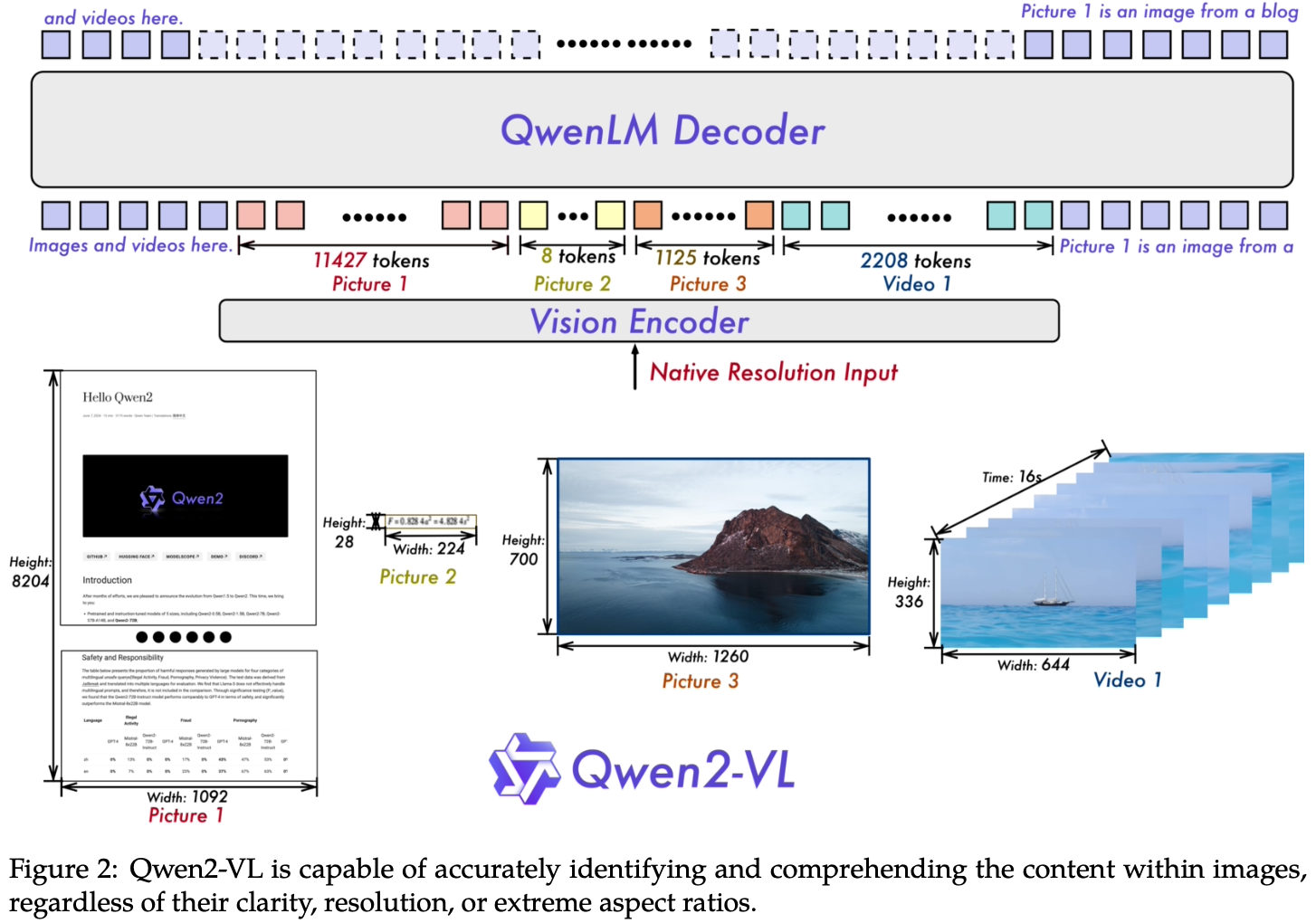
Naive Dynamic Resolution
与 Qwen-VL 不同,Qwen2-VL现在可以处理任意分辨率的图像,动态地将它们转换为可变数量的视觉 tokens。Qwen2-VL 修改了ViT,移除了原始的绝对位置编码,并引入了 2D-RoPE 来捕获图像的二维位置信息。在推理阶段,不同分辨率的图像被打包成单个序列,通过控制打包长度来限制GPU内存使用。此外,为了减少每张图像的视觉tokens,在 ViT 之后使用一个简单的MLP层将相邻的 2×2 tokens压缩成单个token,并在压缩后的视觉 tokens 的开头和结尾放置特殊的 <|vision_start|> 和 <|vision_end|> tokens。因此,一张224×224 分辨率的图像,使用 patch_size=14 的 ViT 编码后,在进入LLM之前会被压缩到 66 个tokens。
回顾 Qwen-VL 中的做法,通过 adapter 来压缩视觉 token 的长度,但是在这一代模型中则取消这一设计,选择更简单的方式直接将变长的视觉 token 拼接到骨干网络中,其背后的原因可能主要还是 Qwen2 能力提升 + Flash Attention 的效率提升。
Multimodal Rotary Position Embedding (M-RoPE)

M-RoPE 将 RoPE 分解为三个组件:时间(temporal)、高度(height)和宽度(width)。
对于文本输入,这些组件使用相同的位置ID,使M-RoPE在功能上等同于1D-RoPE。在处理图像时,每个视觉 token 的 temporal ID 保持恒定,而高度和宽度组件则根据 token 在图像中的位置分配不同的ID。对于视频,它们被视为帧序列,temporal ID为每一帧递增,而高度和宽度组件遵循与图像相同的ID分配模式。这样做的一个好处在于,降低位置ID值,支持更长序列外推。
- 传统方法的问题:
训练时:
文本(100 tokens): ID 0-99
图像(1024 tokens): ID 100-1123
总共: ID 0-1123 ✓ (在训练范围内)
推理时处理更长内容:
文本(100 tokens): ID 0-99
图像1(1024 tokens): ID 100-1123
图像2(1024 tokens): ID 1124-2147
图像3(1024 tokens): ID 2148-3171
...
图像10: ID达到10000+ ✗ (超出训练范围,外推能力差)
- M-RoPE的优势:
训练时:
文本(100 tokens): temporal=0-99, h=0, w=0
图像(1024 tokens): temporal=0, h=0-31, w=0-31
最大ID值: 99 (temporal维度)
推理时:
文本(100 tokens): temporal=0-99
图像1: temporal=0, h=0-31, w=0-31
图像2: temporal=1, h=0-31, w=0-31 ← temporal只需+1
图像3: temporal=2, h=0-31, w=0-31
...
图像100: temporal=99, h=0-31, w=0-31 ✓ (仍在训练范围内!)
Unified Image and Video Understanding
Qwen2-VL 在处理视频输入的时候使用 3D 卷积,能够处理 3D tubes 而不是 2D patches。为了保持一致性,每张图像被视作两个相同的帧,也就是 Time 纬度值是1。为了平衡长视频处理的计算需求与整体训练效率,我们动态调整每个视频帧的分辨率,将每个视频的总tokens数限制在16384。
模型训练
模型训练和 Qwen-VL 一样,仍然是相同的三个阶段训练。
在预训练阶段,专注训练 ViT,利用大量的 image-text 对、OCR 数据、交错的 image-text 文章等数据。这一阶段使用了大约 6000亿 tokens 的语料库,是 Qwen-VL 的 400 倍。
在多任务训练阶段,使用大约 8000 亿 tokens,解冻所有参数进行训练。
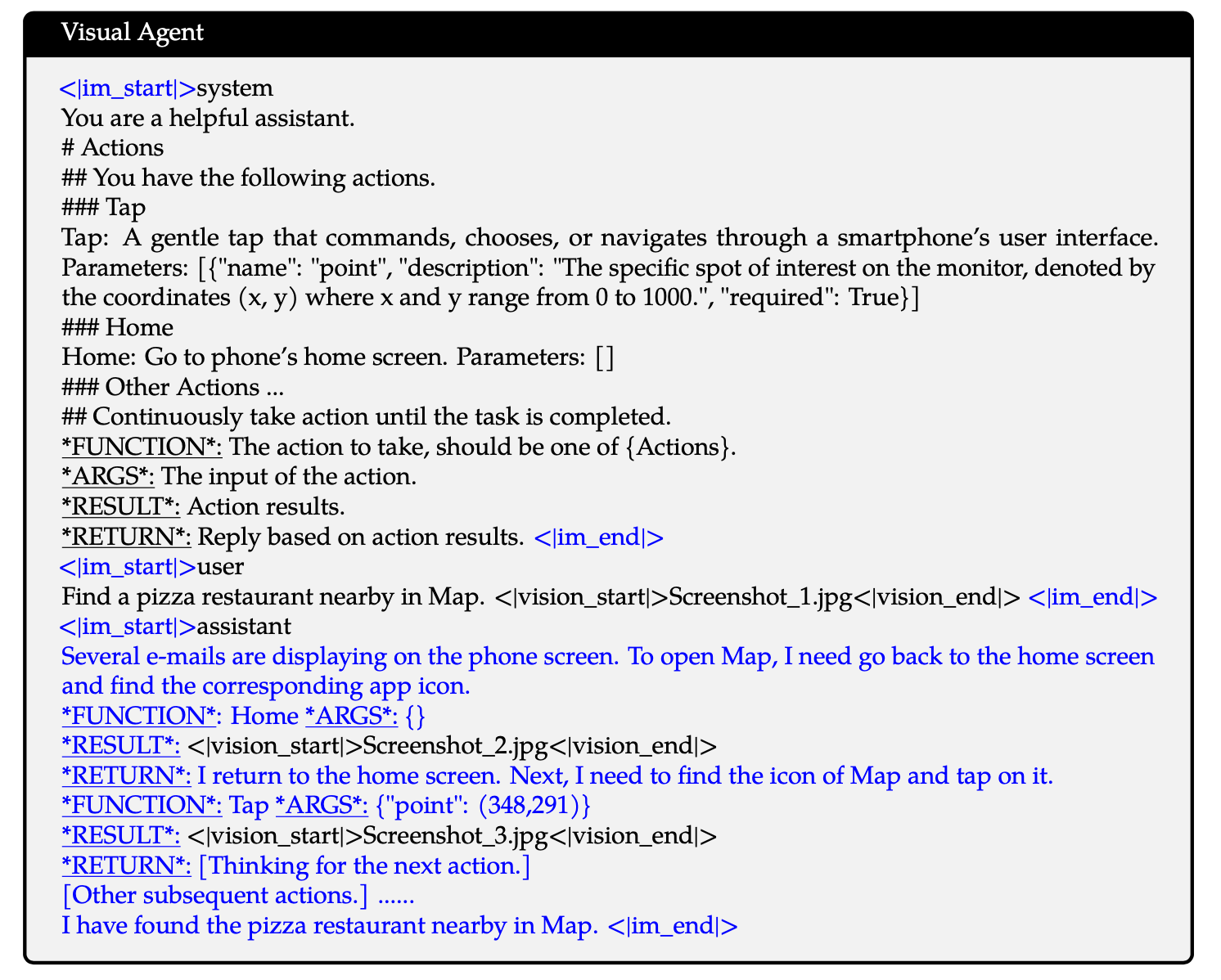
在SFT阶段,同样使用纯文本和多模态两种对话数据。值得注意的是,相比上一代模型,这里还使用了 Agent 数据(如UI操作、机器人控制、游戏和导航),即执行FUNCTION,观察 RESULT,进行推理和规划 RETURN。例如:
Qwen2.5-VL
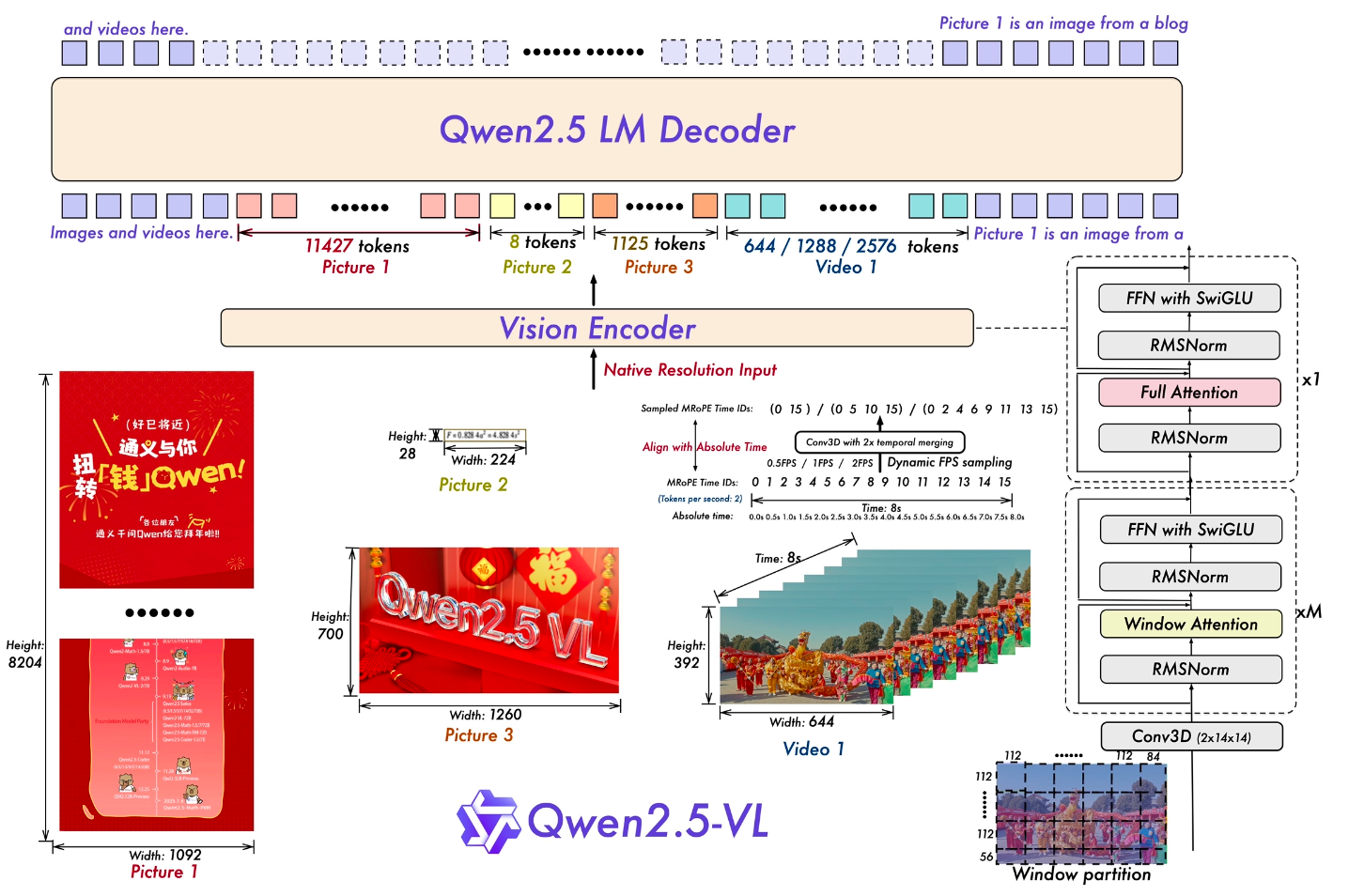
模型设计
ViT 优化
不同于过去两版模型,Qwen2.5-VL 从头训练了 ViT,包括 CLIP 预训练(对比学习)、vision-language 对齐和端到端 fine-tuning。模型设计上,引入了 LLM 中的一些设计,比如 RMSNorm,SwiGLU。除此以外,又重新引入 Window Attention (Qwen-VL 中被证明没什么用,看来还是和 ViT 本身的结构十分相关)。只有 4 层采用 global attention,其它都是采用 112x112 (8x8 patches) 的窗口注意力。 对于视频数据,两个连续帧被分组在一起,例如 [(f1,f2), (f3,f4), (f5,f6), ...] ,从而显著减少了 tokens 的数量。实际上,如果想要更细粒度的时间尺度,可以提高采样的 FPS。
绝对时间戳对齐的位置编码
在Qwen2-VL中,M-RoPE中的temporal位置ID与输入帧数相关联,这没有考虑内容变化的速度或视频内事件的绝对时间。为了解决这一局限,Qwen2.5-VL引入了一个关键改进:将M-RoPE的 temporal 组件与绝对时间对齐。
模型训练
预训练
预训练语料从 Qwen2-VL 的 1.2 万亿 token 增加到了 4 万亿,相对应地,在 2.5 版本的技术报告里,数据的构造篇幅占比也显著提升。
预训练的策略和之前也稍有不同,除了第一阶段仅训练 ViT,第二阶段多任务全参数微调,在第三阶段为了增强模型对长序列、视频和基于 agent 数据的推理能力,纳入了相关的长序列数据。
后训练
后训练包含 SFT 和 DPO 两个阶段。在 SFT 阶段,使用大约 200w 条样本,包含纯文本数据 (50%) 和多模态数据 (50%)。
论文中用了大量篇幅介绍数据的清洗。简单来说,数据的过滤包含规则过滤和模型过滤。例如,在 OCR 任务里面答案是否被截断、HTML 格式是否完整、单元格密度太低等等。模型过滤就是通过多个奖励模型,从多个维度 (例如 query 质量,答案质量,grounding 质量等) 来进行综合打分,根据得分阈值筛选样本。
此外,论文中还提到使用拒绝采样来增强模型的 CoT 推理能力,这一步应该是在 SFT 之后进行优化的,然后再进行的 DPO。不过关于 DPO 的一些细节论文中并没有介绍太多,有可能这个的作用并不是很大吧。
InternVL 2.5
[TBD]
Pixtral 12B
[TBD]