Image Generation
2025年11月10日 · 824 字 · 4 分钟
Flow-GRPO, Qwen Image, etc.
Flow-GRPO
模型
Flow-GRPO 是第一个尝试将 GRPO 和 Flow Matching 结合的工作。它主要解决两方面的挑战:
挑战一:RL 需要随机采样来进行探索,而 Flow Matching 模型是确定性的
挑战二:Flow Matching 采样效率低,而 GRPO 要求高效采样
我们首先来看第一个挑战。Flow Matching 的特点是基于 ODE 方程 $dx_t=v_t dt$,给定起点和模型,它的生成路径是唯一确定的。这会导致两个问题:
首先,概率密度计算困难。GRPO 的损失计算函数中涉及到重要性采样,也就是计算:
$$r_t^i(\theta) = \frac{p_\theta(x_{t-1}^i|x_t^i, c)}{p_{\theta_{\text{old}}}(x_{t-1}^i|x_t^i, c)}$$对于确定性过程,概率要么是0(如果不在确定路径上),要么是1(如果在确定路径上)。这需要计算雅可比矩阵的行列式来估计概率密度:
$$p(x_{t-1}|x_t) = \delta(x_{t-1} - f(x_t)) \cdot \left|\det\frac{\partial f}{\partial x_t}\right|$$其计算复杂度为 $O(d^3)$,成本极高。
其次,由于每次生成图像的轨迹都是一样的(给定相同的初始噪声和提示词),这会导致:生成的一组图像高度相似,使得组内奖励的方差接近0,Group advantage 值无法有效计算。
为了解决第一个挑战,Flow-GRPO 将 Flow Matching 要解决的 ODE 问题转换为了 SDE 问题,即:
$$dx_t = \underbrace{\left(v_t(x_t) + \frac{\sigma_t^2}{2t}(x_t + (1-t)v_t(x_t))\right)}_{\text{漂移项}} dt + \underbrace{\sigma_t dw}_{\text{扩散项}}$$其中:
- $dw$ 表示 Wiener 过程增量(布朗运动)
- $\sigma_t$ 控制生成期间的随机性水平
- 论文中设定为 $\sigma_t = a\sqrt{\frac{t}{1-t}}$
为什么要这样设计 $\sigma_t$?
噪声调度 $\sigma_t = a\sqrt{\frac{t}{1-t}}$ 的设计有以下考虑:
时间依赖性:
- 当 $t \to 0$(接近纯噪声):$\sigma_t \to 0$,扩散较小
- 当 $t \to 1$(接近真实数据):$\sigma_t \to \infty$,但实际会被截断
- 在中间阶段:提供适度的随机性用于探索
与Rectified Flow匹配:
- 这个形式确保转换后的SDE在所有时间步保持与原始ODE相同的边际分布 $p_t(x_t)$
- 即:$p_t^{\text{ODE}}(x_t) = p_t^{\text{SDE}}(x_t), \quad \forall t \in [0,1]$
rollout 伪代码:
# ===== 1. 生成一组样本 =====
group_images = []
group_trajectories = []
group_rewards = []
for _ in range(group_size):
# 1.1 从标准高斯分布采样初始噪声
x_T = torch.randn(1, 4, 64, 64) # 潜在空间
# 1.2 SDE采样轨迹(关键:引入随机性)
trajectory = [x_T]
x_t = x_T
for step in range(num_steps):
t = 1.0 - step / num_steps # 从1到0
dt = -1.0 / num_steps
# 预测速度
v_t = model(x_t, t, prompt)
# 计算噪声水平
sigma_t = sigma_a * torch.sqrt(t / (1 - t + 1e-8))
# SDE更新(关键公式)
drift = v_t + (sigma_t**2 / (2*t + 1e-8)) * (x_t + (1-t)*v_t)
diffusion = sigma_t * torch.sqrt(abs(dt)) * torch.randn_like(x_t)
x_t = x_t + drift * dt + diffusion
trajectory.append(x_t)
# 1.3 VAE解码得到图像
x_0 = x_t
image = vae.decode(x_0)
# 1.4 计算奖励
reward = reward_fn(image, prompt)
group_images.append(image)
group_trajectories.append(trajectory)
group_rewards.append(reward)
接下来我们看第二个挑战。假设我们训练的时候迭代 10,000 次,batch 大小设置为 8,group size 设置为 24,去噪步数设置为 40,那么总前向传播次数为:
$$\text{总次数} = 10,000 \times 8 \times 24 \times 40 = 76,800,000 \text{次}$$如果每次前向传播耗时 0.1 秒,总时间约为 2,133 小时(约89天),非常耗时!如果我们直接减少生成步长(例如从40步降到10步),在传统认知中会导致质量差、模糊、伪影等问题。
Flow-GRPO 的关键发现是:RL训练不需要完美的样本质量,只需要正确的相对质量排序。因此,Flow-GRPO 采用了以下策略:
训练阶段: 使用少量步数(10步)
↓
- 样本质量稍差,但生成速度快4倍
- 相对质量排序仍然正确
- 足以提供有效的学习信号(advantage计算)
推理阶段: 使用完整步数(40步)
↓
- 保证最终输出的高质量
- 用户看到的结果不受影响
实验
Flow-GRPO 主要在三个主要任务上进行评估:
任务1: 组合图像生成 (Compositional Image Generation)
└─ 评估数据集: GenEval
任务2: 视觉文本渲染 (Visual Text Rendering)
└─ 评估数据集: 自定义文本渲染数据集
任务3: 人类偏好对齐 (Human Preference Alignment)
└─ 评估数据集: DrawBench (使用PickScore评估)
在 GenEval 上主要评估模型组合能力,比如生成单个/多个指定物体,指定数量的物体,颜色,空间位置,属性绑定等等。在该数据集上使用规则奖励,比如 counting 任务,如果 prompt 是“生成3只猫”,模型生成了2只,则 $reward = 1-|3-2|/3=2/3$ 。对于Position/Color 任务使用分层奖励机制,例如下面这段示例代码:
def position_color_reward(image, prompt):
"""
空间位置/颜色任务的奖励函数
采用分层奖励机制
"""
# 解析提示词
requirements = parse_prompt(prompt)
# 例: "a red cat to the left of a blue dog"
# requirements = {
# 'objects': ['cat', 'dog'],
# 'count': {'cat': 1, 'dog': 1},
# 'position': 'cat left of dog',
# 'colors': {'cat': 'red', 'dog': 'blue'}
# }
# 使用目标检测器
detections = object_detector(image)
# 第1层: 检查物体计数 (基础奖励)
count_correct = check_count(detections, requirements['count'])
if not count_correct:
# 如果物体数量都不对,只给部分奖励
return partial_reward # 例如 0.0 - 0.3
# 第2层: 检查空间位置或颜色 (完整奖励)
if 'position' in requirements:
position_correct = check_position(detections, requirements['position'])
if position_correct:
return 1.0 # 完全正确
else:
return 0.5 # 物体对但位置错
if 'colors' in requirements:
colors_correct = check_colors(image, detections, requirements['colors'])
if colors_correct:
return 1.0 # 完全正确
else:
return 0.5 # 物体对但颜色错
return 0.5 # 物体对但其他属性不对
# 具体例子
prompt = "a red cat to the left of a blue dog"
# 场景1: 完美
# 图像: 红猫在左,蓝狗在右
count_correct = True # 1只猫1只狗 ✅
position_correct = True # 猫在狗左边 ✅
colors_correct = True # 红猫蓝狗 ✅
reward = 1.0
# 场景2: 物体对,位置对,颜色错
# 图像: 蓝猫在左,红狗在右
count_correct = True # 1只猫1只狗 ✅
position_correct = True # 猫在狗左边 ✅
colors_correct = False # 颜色反了 ❌
reward = 0.7 # 部分正确
# 场景3: 物体对,位置错
# 图像: 红猫在右,蓝狗在左
count_correct = True # 1只猫1只狗 ✅
position_correct = False # 猫在狗右边 ❌
reward = 0.5
# 场景4: 物体数量就错了
# 图像: 2只猫,1只狗
count_correct = False # 物体数不对 ❌
reward = 0.2 # 很低的部分奖励
针对视觉文本渲染任务,通常是要求生成包含文字的图片,例如 “A sign that says ‘{text}’"。针对这一任务,可以通过 OCR 提取生成图片中的文字,然后计算和 ground truth 的编辑距离,来构建奖励函数:$r = max(1 - N_e / N_{ref}, 0)$,其中 $N_e$ 表示最小编辑距离,$N_{ref}$ 表示目标文本的字符数。
DrawBench 评估集是更加全面的评估模型 T2I 的通用能力,包含大约 200 个提示词。不同于另外两个评估集,在这一评估环节会使用 PickScore,一个预训练好的 reward model 来进行图像质量的打分,其内在逻辑会综合考虑图文匹配度以及视觉效果两方面因素。
Takeaways
- 移除 GRPO 中的 KL 约束会使得任务指标提升类似,但是生成图像质量显著下降
- 减少训练部署可以在维持 reward 几乎不变的前提下,显著提高训练速度,最优部署大约在10步训练,40步推理
- group size 如果太小会导致 group advantage 方差大,估计不准确,建议使用 24 或更大
- 噪声系数 $\alpha$ 参数不能过大也不能过小(似乎比较敏感)
Qwen-Image
模型
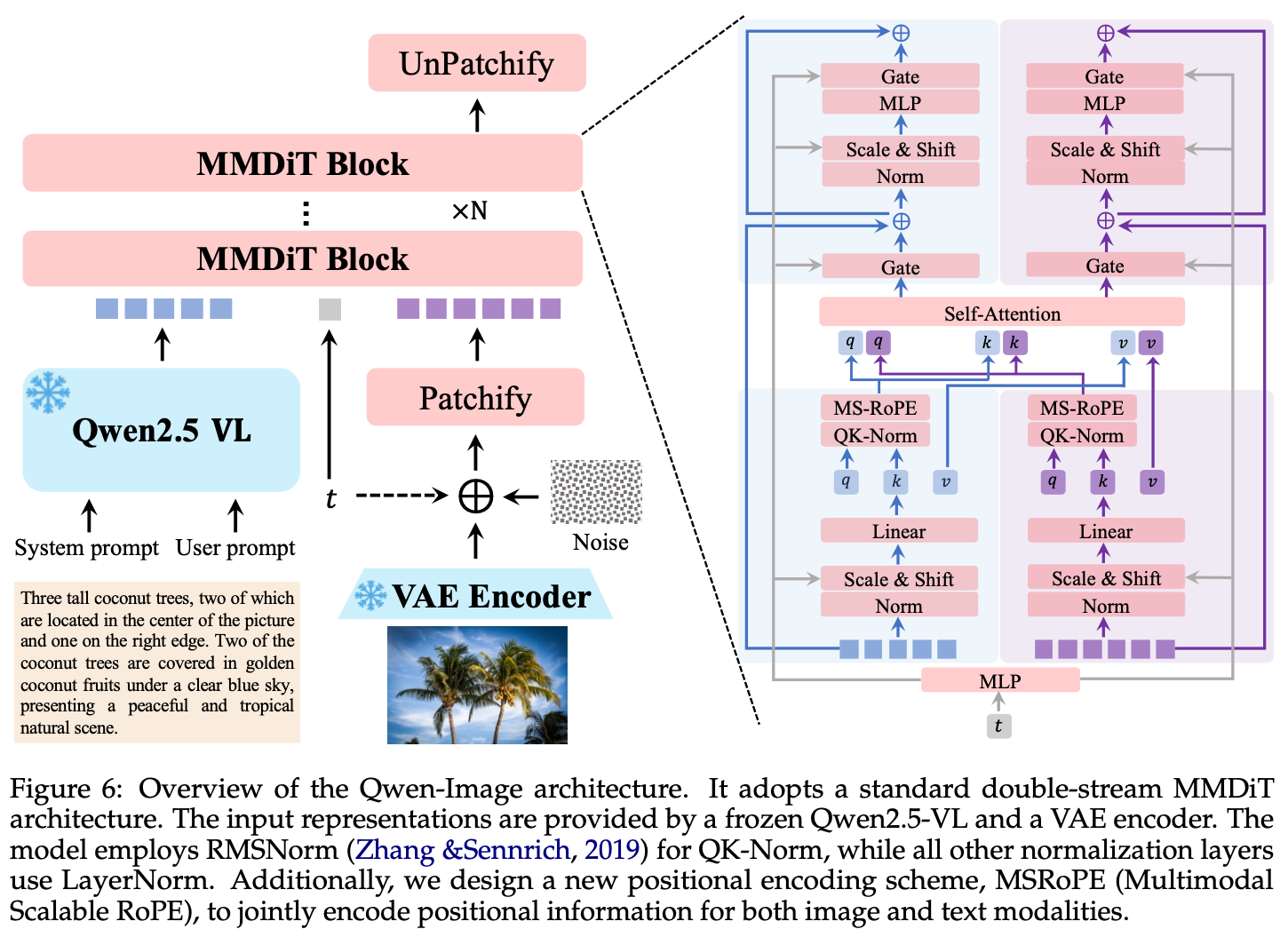
Qwen-Image 首先使用 Qwen2.5 VL 这样一个 MLLM 作为条件编码器从文本里面提取特征,然后使用 VAE Encoder 将图像信息压缩成更为紧凑的表示,最后利用 MMDiT 作为骨干网络,在文本引导下建模噪声和图像隐变量之间的复杂联合分布。
使用 Qwen2.5-VL 编码输入文本
这样做是因为 MLLM 在预训练的时候,已经将 text 和 visual 信息对齐,使得它相比于纯文本的 LLM 而言,更适合进行 T2I 任务;此外,它还支持视觉输入,使得它在执行图像编辑任务的时候,可以提取更好的视觉语义潜入,从而更好遵循指令。
VAE 的设计
在 Qwen-Image 里面,希望构建一个对图像和视频都兼容的通用视觉表示。现有的框架,比如 WAN-2.1-VAE,在图像和视频之间存在性能权衡,导致图像维度的重建效果变差。所以在 Qwen-Image 里面采用了单编码器、双解码器的架构。也就是对于图像和视频输入,共享同一个 Encoder,但是独立使用 Decoder。为此,Qwen-Image 将 WAN-2.1-VAE 的 Encoder 固定,在真实世界文档(PDF,PPT,Poster)以及合成段落上单独微调 Decoder。覆盖字母语言(英文)和表意文字语言(中文)。
MultiModal Diffusion Transformer (MMDiT)
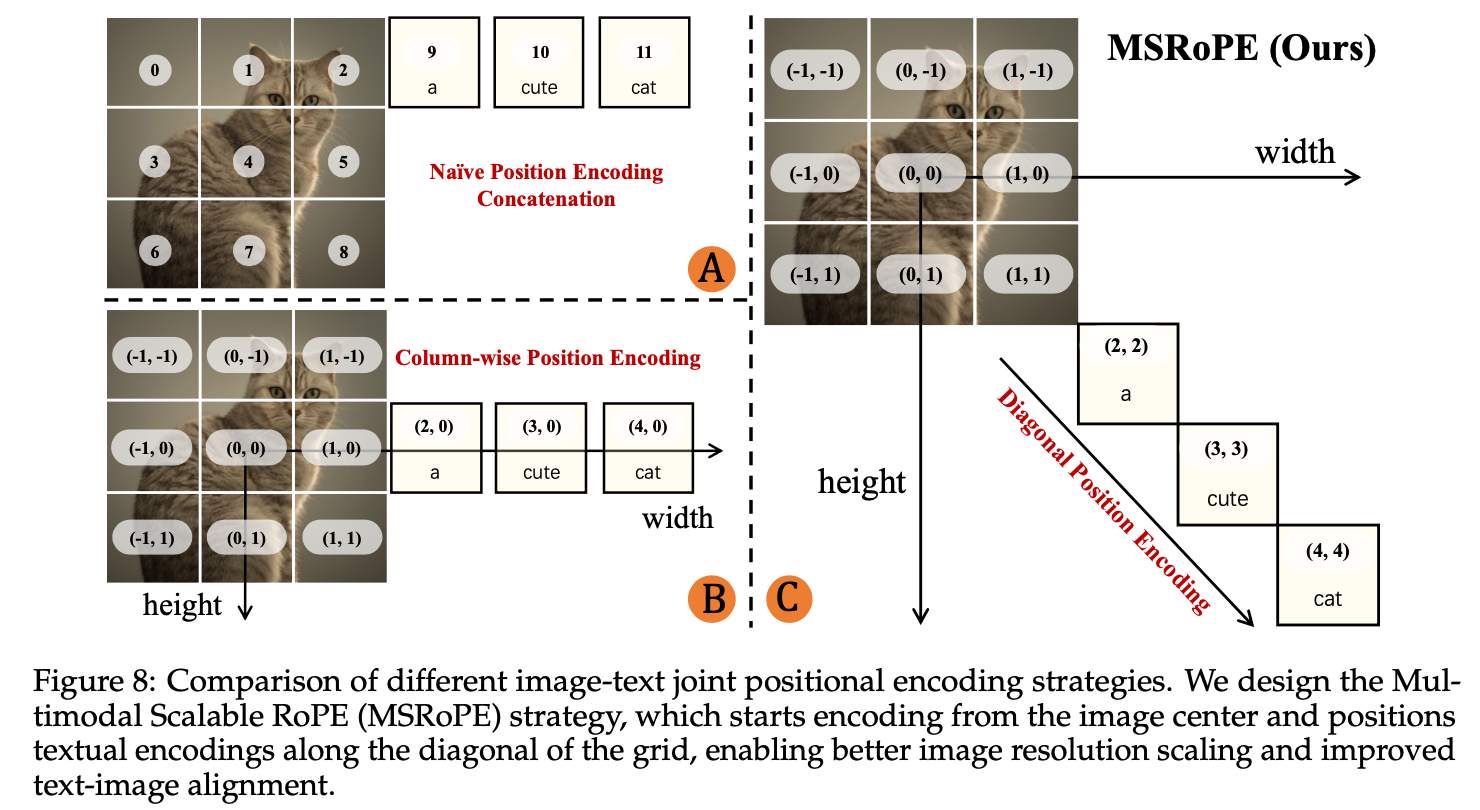
MMDiT 在 Stable Diffussion 3 中首次登场,Qwen-Image 在此基础上进行了一些改动,引入了一个新的位置编码 MSRoPE。
如上图C所示,传统做法直接拼接会导致文本和图像某些行的位置编码重叠。Scaling RoPE 将图像位置编码移到中心区域,但是确定哪一图像行拼接文本token不容易,并且这一行里面图像token和文本token难以区分。MSRoPE 同样文本被视作 2D 张量,但是在两个维度上应用相同的位置ID(沿对角线概念化)。这种设计允许MSRoPE在图像侧保留2D RoPE的分辨率缩放能力,同时在文本侧保持与1D-RoPE的功能等价性,从而无需确定文本的最佳位置编码。
数据
数据包含数十亿 image-text 对,包含四个主要领域:自然(55%)设计(27%)人物(13%)合成(5%)。
数据合成
数据合成有三种策略:
- 为了训练模型识别和省哼罕见字符,采用真实文本+干净背景。例如:
输入: "春眠不觉晓,处处闻啼鸟"(从古诗语料库提取)
处理: 选择字体(如楷体)→ 动态计算布局 → 渲染到白色/浅色背景
输出: 一张只有文字的干净图像
质控: 如果某个字无法渲染(如生僻字缺字体)→ 丢弃整个段落
- 为了让模型理解文字和真实场景之间的关系,采用文字+物理介质+真实场景。例如:
步骤1: 在木板纹理上渲染"OPEN"
步骤2: 将这个"木板"合成到咖啡店门口的照片中
步骤3: 用Qwen-VL生成描述: "咖啡店门口挂着写有'OPEN'的木牌, 背景是砖墙和玻璃门"
- 为了让模型理解和生成复杂的多行、多区域文本布局,采用基于模板的程序化编辑。例如:
模板: PowerPoint幻灯片,包含标题、正文、页脚占位符
程序化替换:
- 标题占位符 → "2024年度总结"
- 正文占位符 → 从语料库提取的业务报告文本
- 页脚占位符 → "第3页 | 机密"
保持: 布局、对齐、字体大小、颜色方案
输出: 结构完整的商务PPT页面
训练
预训练
预训练使用 Flow Matching 训练,原文中强调了训练的 infra,强调采用 Producer-Consumer 框架,在 Producer 中完成 Qwen2.5-VL 和 Encoder 的数据编码任务,Consumer 负责训练 MMDiT 模型。此外,使用 Magatron-LM 进行训练,为了实现张量并行,使用 Transformer-Engine 库构建 MMDiT 模型。
值得关注的是,Qwen-Image 在预训练的时候采用了多阶段训练,逐步提高数据质量、图像分辨率和模型性能:
- 提升分辨率 逐步提升分辨率、多纵横比输入。从 256×256 像素的初始分辨率开始(具有各种纵横比,包括1:1、2:3、3:2、3:4、4:3、9:16、16:9、1:3和3:1),然后增加到640×640像素,最终达到 1328×1328 像素。
- 集成文本渲染 逐步引入包含在自然背景上叠加渲染文本的图像
- 精炼数据质量 训练早期使用大规模数据集,随着训练进行,逐渐采用越来越严格的数据过滤机制来选择高质量样本
- 平衡数据分布 训练过程中逐步平衡数据集在领域和图像分辨率分布方面的平衡
- 使用合成数据 对于超现实主义风格或者包含大量文本内容的高分辨率图像,使用合成数据来补充样本
后训练
模型在经过SFT后,原文介绍了两种不同的 RL 策略:DPO和GRPO。具体而言,使用DPO进行相对大规模的RL,并保留GRPO用于小规模精细RL优化。
- 在 DPO 阶段,给定相同提示词,使用不同的随机种子生成多张图像,然后要求人工选择最好和最差的图像。如果有 reference image,则选择生成图像中最差的作为 rejected 样本;否则选择最好和最差作为 chosen/rejected 样本
- 在 GRPO 阶段,使用 Flow-GRPO 框架进行训练;
多任务训练
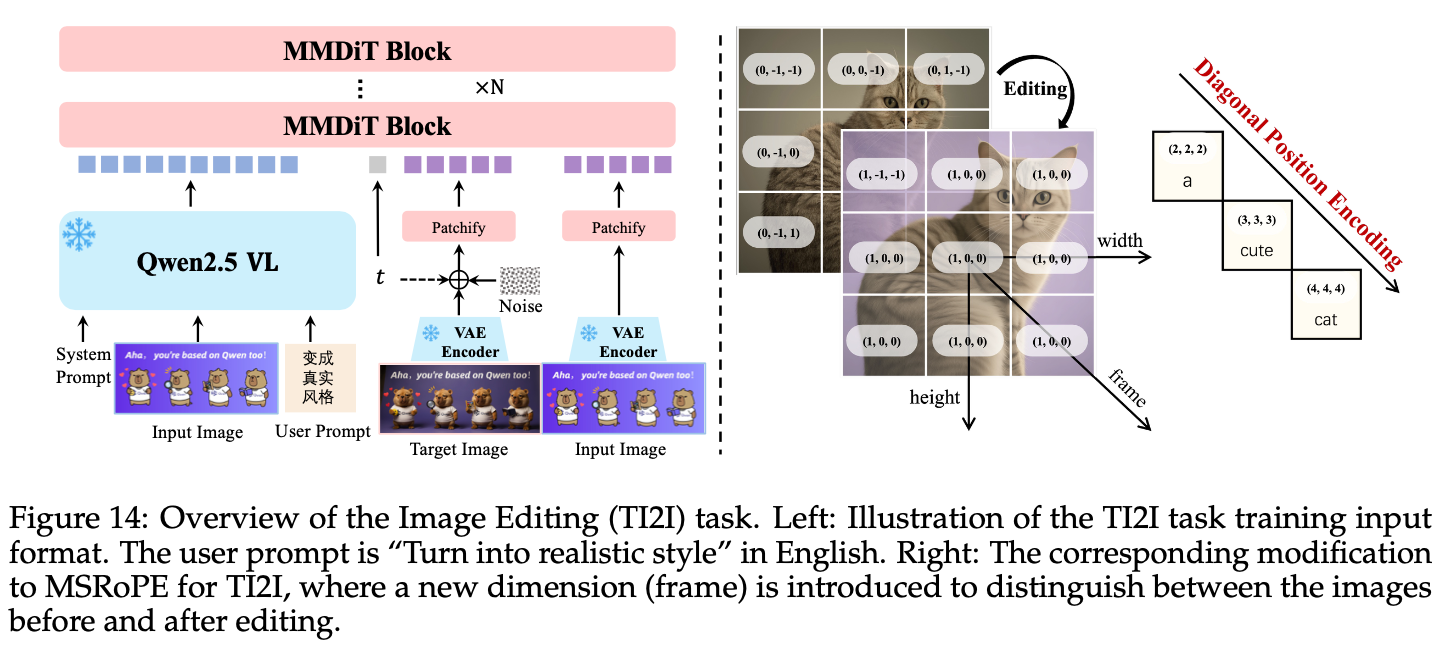
除了 T2I 任务以外,Qwen-Image 还扩展了 TI2T 任务,包括图像编辑、新视图生成等等。如上图所示,为了能够让模型区分多张图像,还引入了额外的帧维度来扩展 MSRoPE。
实验
VAE 重建性能
之前有提到,Qwen-Image 在 WAN-2.1-VAE 基础上微调解码器,针对图像模态单独训练了一个 VAE。其中 Encoder 19M Decoder 25M 参数,量化指标看重建图像的 PSNR 和 SSIM 指标,越高越好。
PSNR 计算的是两张图像的像素级MSE,其单位是分贝,30-40dB质量良好,>40dB质量优秀;SSIM 主要从亮度、对比度、结构三个维度比较图像,通常在[0,1]之间。
T2I 性能
T2I 和 Flow-GRPO 一样,主要看通用生成能力和文本渲染能力。
图像编辑
除了 GEdit / ImgEdit 这两个benchmark以外,还测试了模型处理3D任务的性能,包含新视图合成和深度估计。