Flow Matching
2025年2月11日 · 660 字 · 4 分钟
生成模型是深度学习中的重要研究方向,其核心目标是学习复杂的数据分布并生成新样本。在过去的几年中,从VAE、GAN 到 Diffusion Model,研究者们提出了多种生成模型范式。本文将介绍一个新兴的生成模型方法:Flow Matching,并从其理论发展脉络出发,展现这一方法的独特优势。
在开始之前,让我们通过一个简单的例子来理解Flow Matching的核心思想:想象我们有一团云(简单的高斯分布),我们希望将它逐渐变形成一只猫(复杂的数据分布)。传统的方法可能需要精确计算这个变形过程中的概率变化,而Flow Matching则提供了一种更直观的方式:直接学习"云"变成"猫"的运动轨迹,就像给每个点标注一个"速度向量",告诉它该往哪个方向移动。
本文将按以下框架展开讨论:
- 首先介绍Normalizing Flow的基本原理及其局限性
- 然后探讨Flow Matching的动机和核心概念
- 最后对比Flow Matching与Diffusion Model的异同
1. Normalization Flow
1.1 动机
假设真实样本服从某个未知分布 $p_{\text{data}}(x)$,我们观测到的样本均属于该分布。理论上,从该分布中采样可以生成未观测到的数据(即合成样本)。VAE 和 GAN 这类生成模型的核心思想正是基于观测数据建模真实分布:
- VAE 通过变分推断逼近真实分布,但依赖近似后验分布,可能导致生成样本模糊;
- GAN 通过对抗训练隐式学习分布,但无法直接计算似然,且训练不稳定。
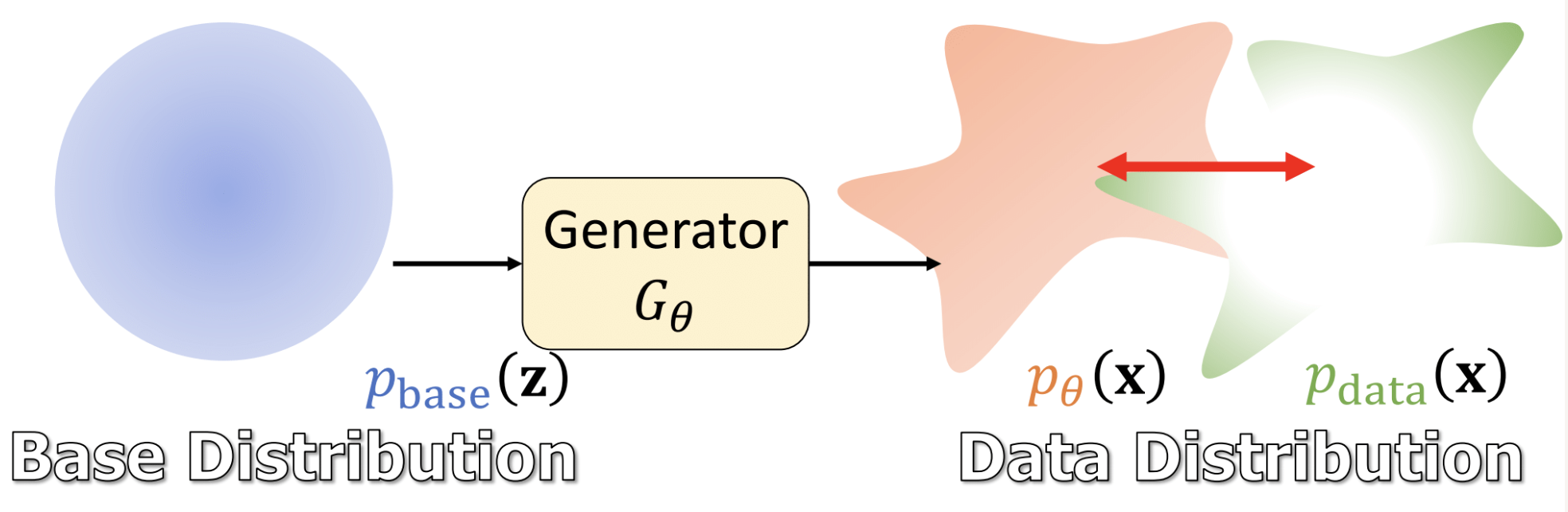
为此,Normalizing Flow提出了一种新的思路:通过设计一系列可逆变换,将简单的初始分布(如高斯分布)精确地映射到复杂的数据分布。这种方法的优势在于可以直接计算似然,从而通过极大似然估计优化模型。
1.2 方法
1.2.1 变量变换公式
根据概率密度守恒定律,若 $x = G_{\theta}(z)$ 是可逆变换且 $G_{\theta}$ 可微,则对任意区域 $\mathcal{Z}$ 和其映射区域 $\mathcal{X} = G_{\theta}(\mathcal{Z})$,有:
结合变量变换定理,可推导出生成分布密度的显式表达式:
其中 $J_{G_{\theta}^{-1}}(x) = \frac{\partial G_{\theta}^{-1}(x)}{\partial x}$ 是逆变换的雅可比矩阵。
这个公式揭示了一个重要的性质:只要我们的生成器 $G_{\theta}$ 是可逆的,并且我们可以计算出它的雅可比矩阵,那么就可以精确地计算出生成分布的概率密度。 这意味着我们可以直接采用极大似然估计来评估模型生成的样本质量,而不需要像GAN那样依赖判别器的反馈。
1.2.2 极大似然估计
模型通过最小化负对数似然损失进行优化:
$$ \mathcal{L}(\theta) = -\mathbb{E}_{x \sim p_{\text{data}}(x)} \left[ \log p_{\theta}(x) \right]. $$将公式(2)代入并展开:
进一步利用 $z = G_{\theta}^{-1}(x)$ 的关系,可等价表示为对隐变量 $z$ 的优化:
1.2.3 NF 的局限性
Normalizing Flow 虽然理论优美,但存在几个关键限制:
- 生成器必须严格可逆,这限制了模型的表达能力
- 雅可比行列式的计算复杂度高,特别是在高维数据上
- 对生成器结构的约束可能影响生成质量
1.3 连续正则化流(CNF)
正则化流需要设计一系列离散的可逆变换来实现分布转换。连续正则化流 (Continuous Normalizing Flow, CNF) 则提供了一个优雅的推广:将离散变换扩展到连续时间域,通过常微分方程(ODE)来描述分布的演化过程。
CNF的核心思想是将分布的变换看作是一个连续的动力学系统。在这个系统中:
- 每个数据点都遵循一条由神经网络定义的轨迹
- 轨迹由向量场驱动(类似物理中的速度场)
- 整体分布的演化满足概率守恒定律
连续性方程
概率密度演化遵循连续性方程:
$$ \frac{\partial p_t}{\partial t} + \nabla \cdot (p_t \cdot u_t) = 0 $$其中 $p_t$ 是时间 t 处的概率密度,$u_t$ 是向量场。
该方程的物理意义在于:概率密度的局部变化率(时间导数)与概率流的净流出率(散度)之和为零,确保概率守恒。
其物理意义类似于人群流动:如果把 $p_t(x)$ 看作人群密度,$u_t(x)$ 看作移动速度,那么 $p_t(x) \cdot u_t(x)$ 就表示单位时间内通过某点的人流量。
似然计算
基于连续性方程,我们可以推导出概率密度的对数似然:
$$ log p_θ(x) = log p_{base}(z) + ∫_{t=0}^1 -div(u_t(x_t, θ)) dt \\ z = x - ∫_{t=0}^1 u_t(x_t, θ)dt $$然而,模型中包含了从 t=0 到 t=1 的积分项,这种积分在实践中无法直接计算,需要使用常微分方程(ODE)求解器来数值求解。
ODE求解器在计算过程中需要多次评估矢量场($u_t$),每次评估都涉及到复杂的计算。当数据规模变大时,计算成本会显著增加。
因此,这限制了模型在实际大规模应用中的使用,进而引出了 Flow Matching 的出现。
2. Flow Matching
2.1 动机
Flow Matching 的提出源于一个关键洞察:我们是否必须显式计算概率密度的变化?如果我们能直接学习数据点是如何"移动"的,是否可以绕过传统方法的限制?
这种思路启发自物理学中的流体动力学:与其追踪水的密度变化,不如直接描述水的流动方向和速度。这就是Flow Matching的核心思想:学习一个描述数据如何演化的向量场。
2.2 方法
2.2.1 流匹配(FM)
不同于正则化流通过最大似然来学习分布转换,流匹配提出直接学习一个矢量场,该矢量场定义了从数据分布到目标分布的演化路径。
流匹配的核心思想是:每个观测样本都可以从一个简单分布(如高斯分布)通过连续演化得到。这种演化由向量场控制,因此优化目标转化为最小化向量场的差异:
$$ \mathcal{L}_{\text{FM}}(\theta) = \mathbb{E}_{t,p_t(x_t)} \left\| v_t(x_t, \theta) - u_t(x_t) \right\|^2 $$其中:
- $v_t(x_t, \theta)$:神经网络建模的向量场(可学习参数 $\theta$)
- $u_t(x_t)$:生成目标路径 $p_t(x)$ 的理想向量场(未知)
- $t \sim \mathcal{U}[0,1]$:时间均匀采样
然而,直接求解这个优化目标非常困难。首先,我们并不知道概率流 $p_t(x)$ 和向量场 $u_t(x)$ 的值。其次,FM 的损失函数计算涉及到高维积分,计算起来十分复杂。为此,Flow Matching 进一步提出了条件流匹配的解决策略。
2.2.2 条件流匹配(CFM)
为解决直接优化 FM 损失函数的困难,条件流匹配(CFM)将全局问题分解为样本级路径。即不要试图同时学习所有数据点的运动,而是为每个数据点分别学习一条路径。
具体而言:对于每个真实数据点 $x_1$,我们定义一条从简单分布到该点的路径;通过优化每条路径上的向量场,最终得到整体的生成模型。下面我们来推导这个方法:
边际向量场
结合贝叶斯定理,我们可以推导边际向量场:
$$ \begin{aligned} u_t(x) &= \int u_t(x|x_1)p(x_1|x)dx_1 \\ &= \int u_t(x|x_1) \frac{p_t(x|x_1) q(x_1)}{p_t(x)} dx_1 \end{aligned} $$CFM 优化目标
回顾Flow Matching的损失函数:
$$ \begin{aligned} \mathcal{L}_{\text{FM}}(\theta) &= \mathbb{E}_{t,p_t(x)} \left\| v_t(x) - u_t(x) \right\|^2 \\ &= \mathbb{E}_{t,p_t(x)} [\|v_t(x)\|^2 - 2 \cdot v_t(x)u_t(x) + \|u_t(x)\|^2] \\ \end{aligned} $$代入边际向量场表达式,我们可以得到:
$$ \begin{aligned} \mathbb{E}_{x_t \sim p_t(x)}[2 \cdot v_t(x)u_t(x)] &= 2 \cdot \int v_t(x_t) \cdot \frac{\int u_t(x_t|x_1)p_t(x_t|x_1) q(x_1)dx_1}{p_t(x_t)} p_t(x_t)dx_t \\ &= 2 \cdot \int \int v_t(x) u_t(x_t|x_1)p_t(x_t|x_1) q(x_1) dx_1 dx_t \\ &= 2 \cdot \mathbb{E}_{x_t \sim p_t(x_t|x_1), x_1 \sim q(x_1)} [v_t(x_t) \cdot u_t(x_t|x_1)] \end{aligned} \\ $$因此,我们可以将 FM 的损失函数转换为条件形式:
$$ \begin{aligned} \mathcal{L}_{\text{FM}}(\theta) &= \mathbb{E}_{x_t \sim p_t(x_t|x_1), x_1 \sim q(x_1)} [\|v_t(x)\|^2 - 2 \cdot v_t(x_t)u_t(x_t|x_1) + \|u_t(x_t|x_1)\|^2 + \|u_t(x_t)\|^2 - \|u_t(x_t|x_1)\|^2 ] \\ &= \mathbb{E}_{x_t \sim p_t(x_t|x_1), x_1 \sim q(x_1)} \left\| v_t(x) - u_t(x|x_1) \right\|^2 \\ &+ \mathbb{E}_{x_t \sim p_t(x_t|x_1), x_1 \sim q(x_1)} [\|u_x(x_t)\|^2]\\ &+ \mathbb{E}_{x_t \sim p_t(x_t|x_1), x_1 \sim q(x_1)} [\|u_t(x_t|x_1)\|^2] \end{aligned} $$因为后面两项并不涉及我们要优化的网络参数 $v_t(x_t, \theta)$,因此可以舍弃。
这就得到了 CFM 的最终优化目标:
$$ \mathcal{L}_{\text{CFM}}(\theta) = \mathbb{E}_{t, q(x_1), p_t(x|x_1)} \left\| v_t(x) - u_t(x|x_1) \right\|^2 $$这个目标函数的优势在于:
- 避免了计算复杂的边际分布
- 可以针对每个数据点独立优化路径
- 训练过程更加稳定和高效
2.2.3 CFM 中的训练采样策略
在CFM的训练过程中,我们需要考虑两个关键的采样问题:中间点 $x_t$ 的采样和条件向量场的设计。
中间点 $x_t$ 的采样
对于损失函数中的 $x_t$,最常用的采样方式是线性插值:
$$ x_t = (1-t)x_0 + tx_1 $$其中:
- t是从[0,1]均匀采样的时间点
- $x_0$ 是从初始分布(如标准正态分布)采样的点
- $x_1$ 是目标数据点
这种采样方式的优势在于:
- 保证了在 $t=0$ 时得到 $x_0$,在 $t=1$ 时得到 $x_1$
- 提供了一条直观的线性轨迹
- 计算简单且数值稳定
条件向量场的设计
在实际实现中,条件向量场 $u_t(x|x_1)$ 是可以自定义的。最简单和常用的设计是线性插值:
$$ u_t(x|x_1) = x_1 - x $$这种设计的物理含义是:在时间 $t$ 处的点 $x$,其运动方向应该指向目标点 $x_1$。这样设计的好处是:
- 简单直观:向量场直接指向目标位置
- 保证收敛:如果完美地学习了这个向量场,那么轨迹终点一定是目标点 $x_1$
- 计算高效:不需要复杂的计算就能得到向量场的值
除了线性插值,还可以设计其他形式的条件向量场,比如:
- 加入噪声的线性插值:$u_t(x|x_1) = x_1 - x + \epsilon$,其中$\epsilon$是随机噪声
- 基于距离的加权:$u_t(x|x_1) = w(t)(x_1 - x)$,其中$w(t)$是时间相关的权重函数
选择合适的条件向量场对模型的性能有重要影响。通常来说,向量场应该满足:从初始分布能够平滑地演化到目标分布,且路径应该尽可能简单和稳定。
3. Flow Matching vs Diffusion
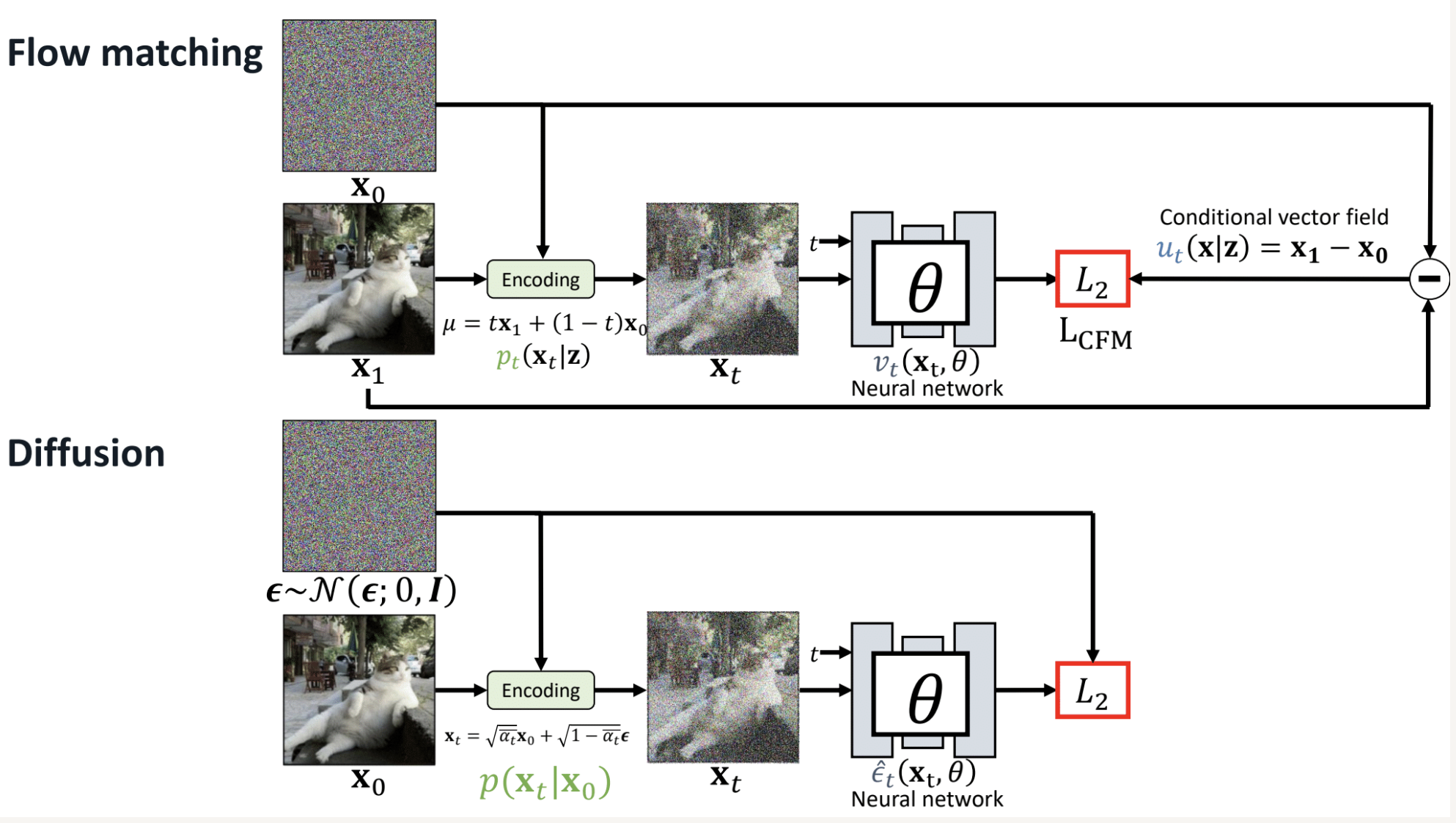
Diffusion Model 和 Flow Matching 在 motivation 上有明显的区别。前者的思想在于,通过逐步加噪声,把数据变成简单的高斯噪声,反过来,让模型学习逐步去噪,从噪声恢复数据。而后者的研究问题是能否找到从噪声到数据的"最短路径"?为此在数据和噪声之间构造直线插值,让模型学习沿着这条直线的速度场。后者的优势在于路径简单,采样更快(可以用更少的步数)。
使用Diffusion Model (如SD 1.5):
# 1. VAE编码 (与Flow完全相同)
latent = vae.encode(image) # [B,3,512,512] → [B,4,64,64]
# 2. Diffusion前向过程
noise = torch.randn_like(latent)
t = random_timestep()
alpha_t = get_alpha(t)
noisy_latent = sqrt(alpha_t) * latent + sqrt(1-alpha_t) * noise
# 3. U-Net预测噪声
predicted_noise = unet(noisy_latent, t, text_embedding)
# 4. 训练损失
loss = mse_loss(predicted_noise, noise)
# 5. VAE解码 (与Flow完全相同)
generated_image = vae.decode(denoised_latent)
使用Flow Matching (如SD 3):
# 1. VAE编码 (完全相同!)
latent = vae.encode(image) # [B,3,512,512] → [B,4,64,64]
# 2. Flow Matching插值
noise = torch.randn_like(latent)
t = random_t()
latent_t = t * latent + (1-t) * noise # 直线插值
# 3. DiT预测速度
predicted_velocity = dit(latent_t, t, text_embedding)
# 4. 训练损失
true_velocity = latent - noise
loss = mse_loss(predicted_velocity, true_velocity)
# 5. VAE解码 (完全相同!)
generated_image = vae.decode(final_latent)