如何让大语言模型听到声音(一)
2024年8月8日 · 245 字 · 2 分钟
本文介绍了音频数据的基本概念、音频信号的预处理流程、音频相关任务以及在深度学习领域,处理音频信号的两种常见架构。
了解音频数据
1. 频率 & 振幅 & 位深
声音的本质是连续信号,要想让物理设备捕获这种连续值,则需要通过采样的方式。这一过程通常涉及几个关键术语:
- 采样率:即一秒钟内进行采样的频率,以赫兹 (Hz) 为单位。根据奈奎斯特极限,从信号中能够捕获的最高频率正好是采样率的一半。对人类而言,声音的可听频率低于 8kHz,更高频的声音信号人耳是听不到的。因此,16 kHz 的采样率对于处理音频而言足矣。但是如果采样率低于 8kHz,就会丢失一些信息,导致声音变得沉闷。如果训练样本中的音频频率不一致,则需要引入重采样(resampling)的预处理步骤来确保采样频率的一致性。
- 振幅:声音是由人类可听频率内的气压变化产生的,其中声压的级别用振幅表示,以分贝 (dB) 为单位。例如,低于 60dB 人耳就很难感知到。
- 位深:刻画振幅值的度量精度。常见的位深有 16-bit 和 24-bit,这些都是整数样本,浮点数样本是 32-bit。
2. 波形 & 频谱 & 光谱
波形图是基于采样点上振幅值所表示的曲线图,横轴是时间,纵轴是振幅值。它记录了音频信号的强度随时间变化的特征。
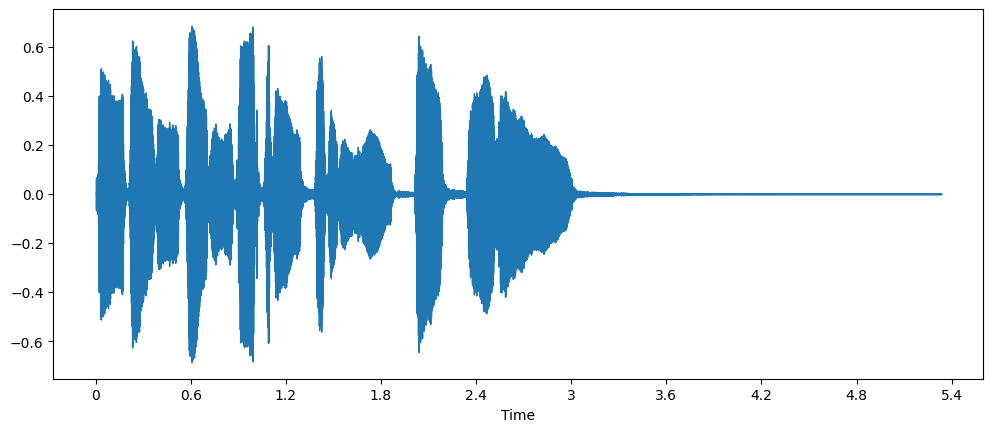
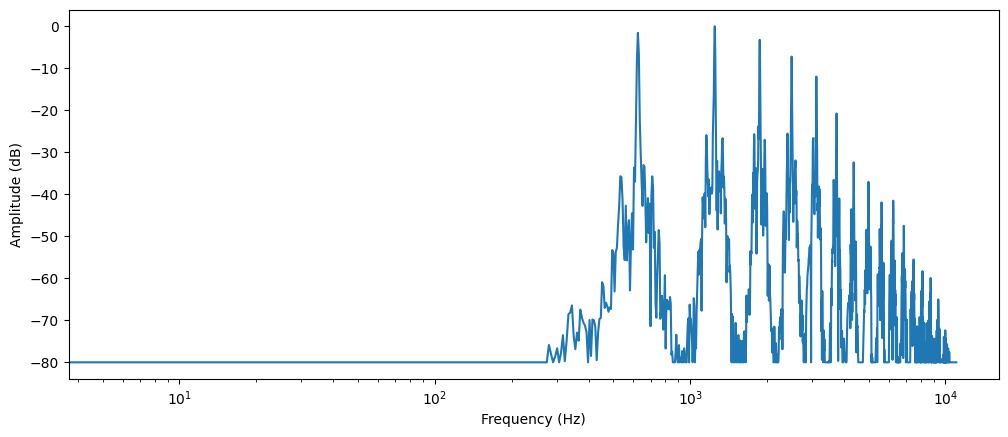
频谱是波形数据经过离散傅立叶变换得到的,横轴是频率,纵轴是振幅值。它记录了音频信号的强度随频率变化的特征。
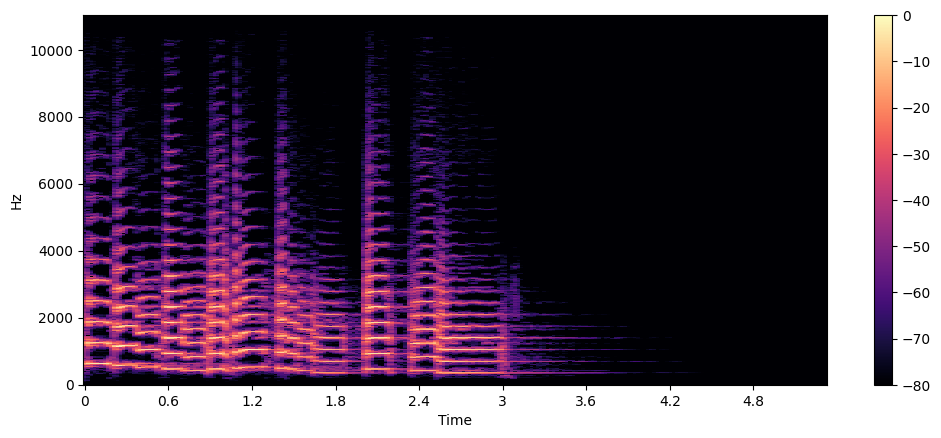
波形图和频谱图刻画的是振幅在时间/频率维度的变化,光谱图则表示频率在时间维度上的变化。它的基本思想是对时间进行微分,在每个极短的时间窗口内进行傅立叶变化,得到该时刻的频谱,最后将所有时刻的频谱拼接起来,振幅值大小用颜色深浅表示。
人类的听觉系统对较低频率的变化比对较高频率的变化更敏感,这种灵敏度随着频率的增加而呈对数下降。梅尔谱图考虑到这一特性,对频率进行梅尔滤波。在 Whisper 中的输入就是梅尔谱图,每个样本的大小是 [频率维度,时间帧数]。如果采用 80 个 Mel 滤波器,并将音频信号划分为 3000 帧,那么梅尔谱图的特征大小就是 [80, 3000]。
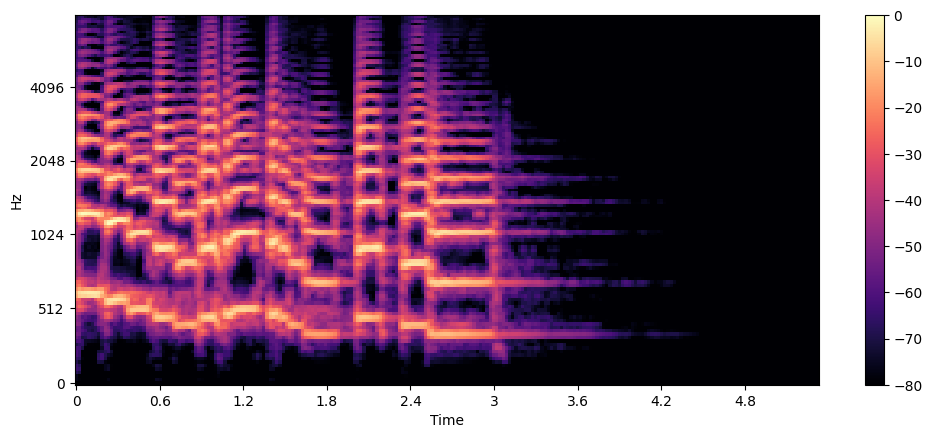
梅尔光谱图可以捕捉到对人类感知而言更有意义的信号,因此在语音识别、音色分类等任务中应用较广。但相比于标准光谱图,梅尔光谱图由于引入滤波操作,会导致信号的过滤,使得从梅尔光谱图转换回波形图变得比较棘手,需要引入 HiFiGAN 这种模型来解决。
音频信号的预处理流程
第一步:重采样
大多数深度学习模型都是基于 16 kHz 采样的音频信号进行训练的,为了和这些预训练模型保持一致,我们首先需要对自己的数据集进行重采样(如果原始数据采样频率不是 16 kHz)。
from datasets import Audio
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
下面两张图是采样前后的直观对比,可以看到将 8 kHz 重采样到 16 kHz 之后多了更多的样本点。
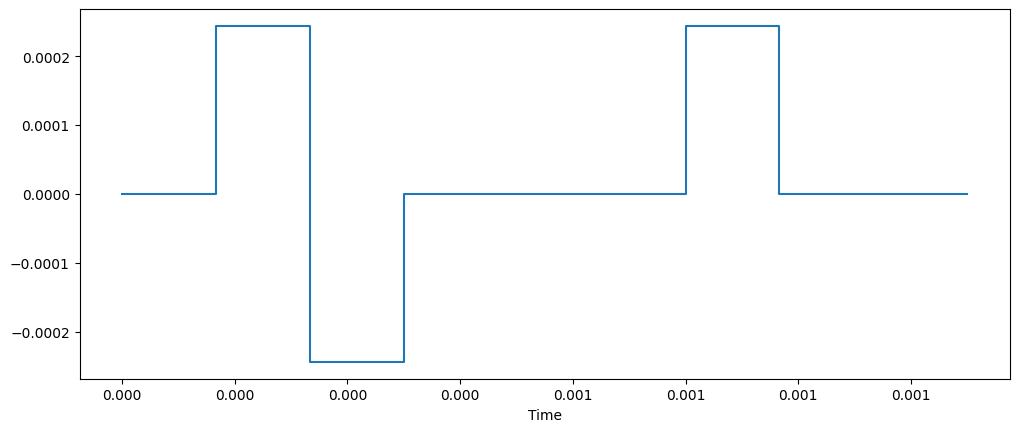
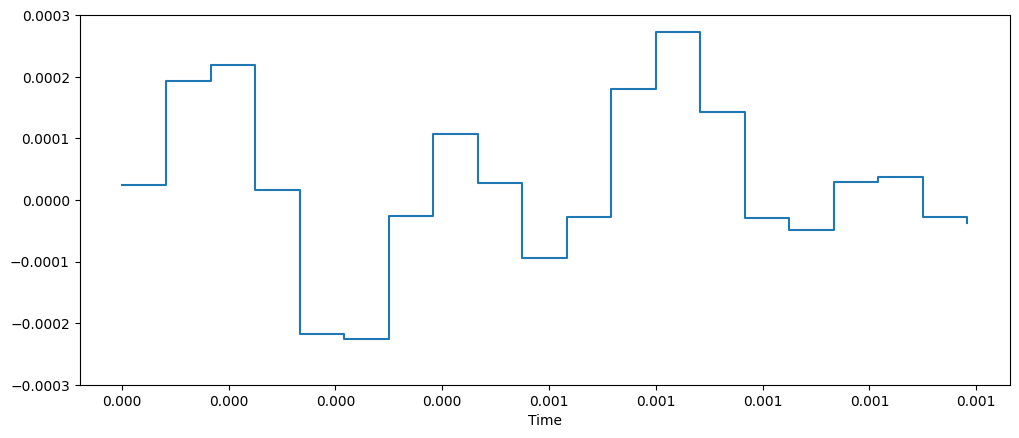
第二步:过滤时长较长的数据
为了防止推理或者训练的时候内存不足,可以限制数据的时长,将时长超过一定阈值的样本从原始数据中删掉。
第三步:特征提取
原始音频数据只有振幅波形,还需要从中抽取更丰富的特征用于模型训练。以 Whisper 为例,其特征提取包含两个部分:
- 填充/截断,控制每个样本长度都是 30 秒
- 将音频矩阵转换为对数梅尔光谱图作为输入特征
音频相关的任务
- 音频分类:歌曲识别
- 自动语音识别 (ASR):将讲者说话的内容自动转录成文字
- 声纹分割 (speaker diarization):将播客音频中不同讲者的音频分离开来
- Text to Speech:将文字转录为人声
- Voice Conversation:输入和输出都是音频
用于处理音频信号的 Transformer
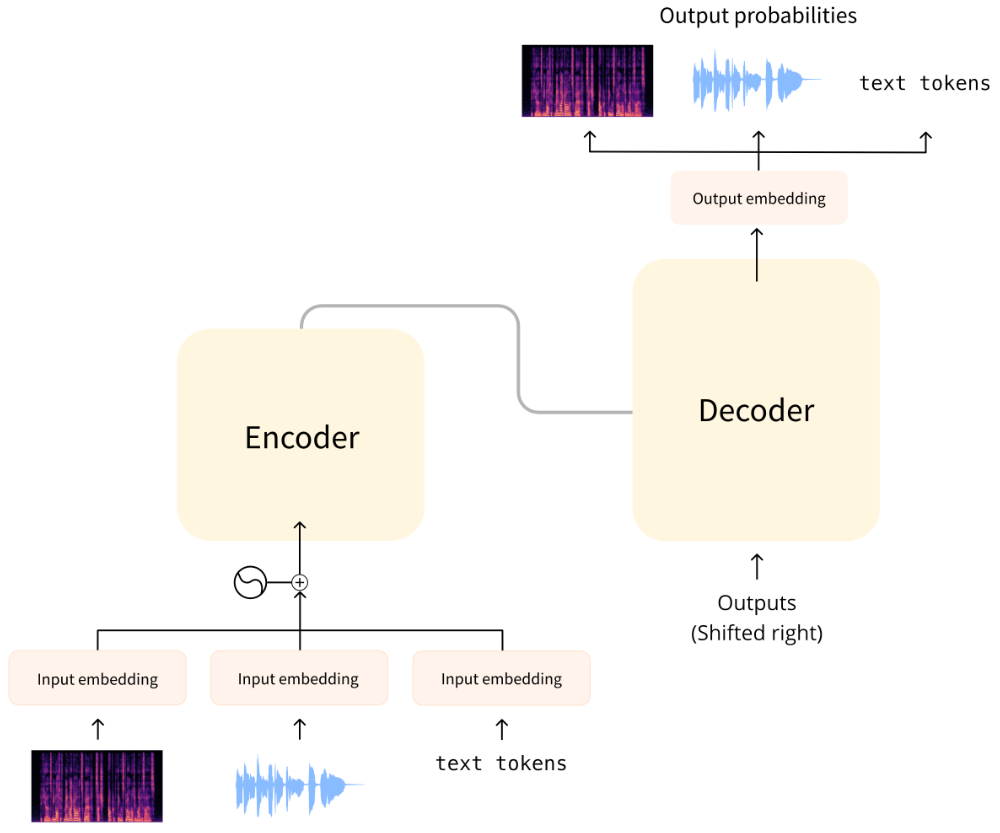
模型的输入可以是文本、波形、频谱。对于波形和频谱的输入,可以采用 CNN 来作为特征提取器得到初始表征。模型的输出一般是文本或者频谱,如果想得到波形则可以对频谱进行逆变换。
CTC 架构
CTC 全称是 Connectionist Temporal Classification,直译过来就是联结主义时序分类,这是用于训练早期语音模型的损失函数。比如 Wav2Vec2.0 就采用该损失用于下游语音识别任务的微调。在 Wav2Vec2.0 中,模型采用 Temporal Convolution 作为特征抽取器,Transformer 作为编码器。
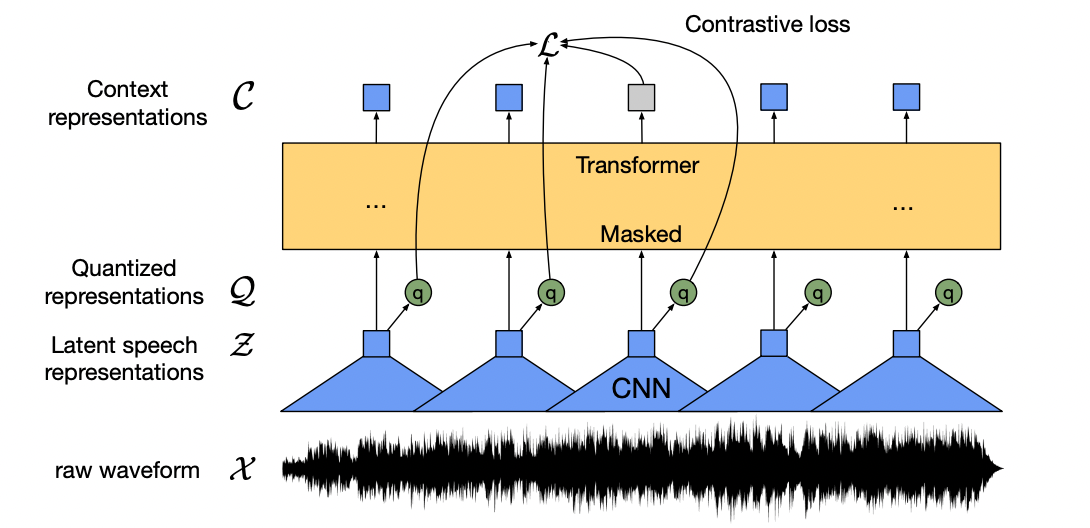
具体而言,Wav2Vec2.0 首先用卷积层将初始的音频信号离散化,得到初始的音频表征 $\mathcal{Z}$,注意这里采用的是有 overlap 的滑移窗口。表征 $\mathcal{Z}$ 随后有两个去处:
- 输入 Transformer 编码器得到语义表征 $\mathcal{C}$。
- 经过量化得到量化表征 $\mathcal{Q}$。这里的量化表征可以看作对连续的 $d$ 维表征空间进行离散化,它首先预设有 $G$ 个 $d/G$ 维的子空间,每个子空间里有 $V$ 个条目 (entries),音频表征 $z \in \mathbb{R}^{d}$ 可以转换为 $G$ 个子空间中原型向量 $e \in \mathbb{R}^{V \times d/G}$ 的组合。基于这一思想,我们可以对初始表征 $z$ 进行映射变换得到索引矩阵 $\mathcal{I} \in \mathbb{R}^{G \times V}$,随后将 $G$ 个子空间中索引概率最大的那一个条目 $i = \text{argmax}\_{j} p\_{g,j}$ 拿出来拼接并进行线性变换,得到量化表征 $q \in \mathbb{R}^{f}$。
这里对比学习不是作用于 $\mathcal{Z}$ 和 $\mathcal{C}$ ,而是引入 product quantization 操作得到量化表征 $\mathcal{Q}$。可以将量化表征看作是 nn.Embedding,它是有限向量的集合,因为量化表征是 G 个子空间有限条目的线性变换而来,因此它也是离散的。
在预训练阶段,Wav2Vec2.0 采用语义表征 $\mathcal{C}$ 与量化表征 $\mathcal{Q}$ 之间的对比学习损失和量化表征 $\mathcal{Q}$ 的熵作为损失函数。在微调阶段,Wav2Vec2.0 采用 CTC 损失。假设这里的音频对应文本是 “hello”,经过卷积后得到 20 个 token,这显然和目标文本(5 个字母)不对齐,因此需要用 CTC 损失。在 CTC 中,我们考虑 20 个 token 预测值的排列组合,得到所有这 5 个字母按照 “h -> e -> l -> l -> o” 顺序构成的序列,计算它们的概率和。微调阶段就是希望这个概率最大,比如这个例子中预测值可能是 “hhheeeeelllllllllloo”,这时候再进行解码即可(连续字母去重)。
Seq2Seq 架构
在 CTC 架构中,输入和输出都是相同的长度,因此在进行 ASR 等任务时需要引入 CTC 来实现文本对齐。但是在 Seq2Seq 架构中,因为模型采用生成式理念,因此输入和输出的长度可以不一致。比如下面 Whisper 架构:

在 Whisper 中,输入是音频信号转换的梅尔频谱图,输出是文本。